CompileTime - 컴파일 단계_1
Compile
컴파일 단계 과정
컴파일 단계는 전처리된 소스코드를 최적화된 중간 코드 또는 어셈블리 언어를 생성한다.
전처리된 소스 코드에서 어휘 분석, 구문 분석, 의미 분석, 중간 코드 생성, 최적화 과정을 거친다.
중간 코드와 어셈블리 코드
중간 코드
플랫폼 독립적인 코드로, 하드웨어와 운영 체제에 종속되지 않도록 설계
주로 최적화 및 타겟 기계어로의 변환에 사용된다.
특징
하드웨어 독립적, 다양한 기계 아키텍처에서 실행될 수 있다.
컴파일러의 중간 단계에서 생성, 기계어로 직접 변환되기 전 여러 최적화 작업을 거친다.
3주소 코드, 세미콜론 코드 같은 형식이 중간 코드로 사용된다.
어셈블리 코드
특정 하드웨어 아키텍처에 맞는 기계어에 대응하는 저수준 코드
특징
- 하드웨어 의존적, 각 프로세서 아키텍처에 맞는 명령어 집합을 사용
- 사람이 읽을 수 있도록 기계에 명령어를 영어같이 표현.
- 어셈블리 코드는 기계어 코드로 직접 변환될 수 있으며, 어셈블러가 변환한다.
- 타겟 기계에서 직접 실행 가능한 형태로 변환한다.
둘의 가장 큰 차이점은 하드웨어 종속성이다.
어휘 분석(scanning)
원시 코드(소스 코드)를 어휘 항목(lexemes)으로 나누어 토큰(token)을 생성하는 단계다.
사용하는 용어들
- 어휘항목 (lexeme): 소스 코드에 존재하는 의미있는 키워드
- 패턴 (pattern): 토큰이 어휘항목을 서술하는 규칙, 정규문법에 따라 표현된다.
- 토큰 (token): 토큰 이름과 속성값으로 구성되는 데이터 쌍으로, 각 토큰은 토큰의 패턴에 부합하는 어휘항목을 갖는다.
어휘 분석 단계에선 어휘 항목을 식별하기 위해 정규 표현식을 사용해 특정 패턴을 찾는다.
정규 표현식 Regular Expression
텍스트에서 특정 패턴을 찾고, 그 패턴에 맞는 문자열을 처리하는 도구
C++에서도 사용 가능하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
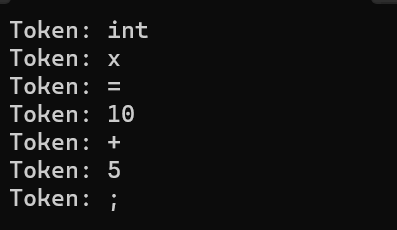
void RegularExpression()
{
string text = "int x = 10 + 5;";
regex token_pattern(R"(int|x|[0-9]+|[+\-*/=;])");
sregex_iterator iter(text.begin(), text.end(), token_pattern);
std::sregex_iterator end;
while (iter != end)
{
cout << "Token: " << iter->str() << endl;
++iter;
}
}
정규 표현식의 순서
정규 표현식에선 패턴을 어떻게 해석할 것인지에 대한 우선순위가 있기에 순서가 중요하다.
a(b|c)*d
해석
1. 문자열 시작은 반드시 a 여야 한다.
2. b또는 c는 0번 이상 반복될 수 있다.
3. 문자열 끝은 반드시 d여야 한다.
각 토큰은 특정한 패턴을 따른다.
- id : 첫 글자가 숫자가 아닌 특수문자를 포함하지 않는 문자열
- number : 모든 숫자, 문자 e를 제외한 문자가 있으면 패턴에 위배
- if : if 문자열만 부합
토큰은 언어에 따라 달라지고, 컴파일러에 따라서도 달라질 수 있다.
어휘 분석기가 원시 코드를 읽고, 토큰으로 변환해 구문 분석을 위한 입력으로 제공한다.
내 생각
토큰을 생성할 때, 띄어쓰기를 기준으로 토큰을 만들면 되지 않나? 라고 생각했지만, 문제점이 있었다.
- 연산자와 구분 기호 처리 연산자와 구분 기호는 띄어쓰기 없이도 붙어있을 수 있다.
ex) 10+20; 띄어쓰기가 없으므로 토큰을 “10”, “+”, “20”, “;” 로 나눌 수 없음 - 문자열 처리 문자열 리터럴은 띄어쓰기와 무관하게 하나의 토큰으로 처리해야함
ex) cout « “Hello, World!”; -> “Hello, World!” 자체가 토큰이 되어야 한다.
때문에 어휘 분석기는 문자 단위로 소스 코드를 스캔하고, 숫자, 식별자, 연산자, 키워드 등을 인식한다.
또한 토큰을 인식할 때 우선순위가 존재한다.
만약 int = 10; 이 주어졌을 때, int는 키워드로 해석 가능하고, 식별자로도 해석 가능하다.
우선순위 규칙
- 길이가 긴 패턴 우선
- =(대입 연산자)와 ==(동등 비교 연산자) 중, 입력이 ==일 때 = 2개가 아닌 ==를 우선 선택
- 고정 키워드 우선
- 예약어는 식별자보다 우선 선택
- int는 항상 키워드로 인식된다.
- 정규 표현식이 정의된 순서로 우선순위 지정
유한 상태 오토마타
유한한 수의 상태를 가지는 추상적인 계산 모델.
유한 상태 오토마타는 하나의 초기 상태에서 조건에 따라 상태를 전의해 다양한 상태 중 하나로 변환하며, 이는 정규 표현식과 유사하게 동작한다.
구성 요소
- 상태의 집합 : 유한한 상태의 모음
- 입력 알파벳 : 입력 심볼의 집합
- 전이 함수 : 현재 상태와 입력에 따라 다음 상태를 결정하는 함수
- 초기 상태 : 시작 상태
- 수용 상태 : 입력 문자열을 수용하는 상태의 집합
공통점
- 정규 표현식은 문자열 패턴을 기술하는 데 사용
- 유한 상태 오토마타는 동일한 패턴을 상태 전이 모델로 표현해 문자열을 인식
예시 1)
정규 표현식 a(b|c)*
a로 시작하고 b 또는 c가 0번 이상 반복
정규 표현식으로 설명
a: 문자열의 시작은 항상a(b|c):b또는c중 하나를 선택*: 선택된 문자가0번 이상 반복
유한 상태 오토마타로 설명
- 초기 상태
q0에서 시작 - 입력이
a라면q1으로 이동 - 상태
q1에서 입력이b또는c라면 다시q1으로 반복 - 상태
q1이 수용 상태
예시2) 정규 표현식 : [0-9]+
[0-9] : 숫자 0부터 9까지 중 하나.
+ : 하나 이상의 숫자가 반복
q0 에서 입력이 0-9라면 q1으로 이동
q1에서 0-9를 입력 받으면 q1 유지
상태 q1이 수용 상태
이처럼 정규 표현식의 연산(|, *, +)은 유한 상태 오토마타의 상태 전이(선택, 반복)와 동일한 의미를 가진다.
때문에 정규 표현식과 유한 상태 오토마타는 상호 변환이 가능하다.
DFA/NFA
유한 상태 오토마타는 결정적 유한 상태 오토마타(DFA)와 비결정적 유한 상태 오토마타(NFA)로 구분할 수 있다.
DFA : 모든 상태에서 주어진 입력에 대해 하나의 경로만 존재
NFA : 특정 상태에서 입력에 따라 여로 경로로 이동 가능
정규 표현식을 유한 상태 오토마타로 변환하기에는 NFA가 더 쉽고, 만들어진 NFA를 DFA로 변환할 수 있다.
오류 검출
어휘 분석 단계에서 오류 검출은 일부만 수행한다.
토큰을 추출하는 과정에서 간단한 오류는 확인 가능하지만, 문법적 오류나 논리적 오류는 주로 구문 분석 단계에서 처리된다.
어휘 분석 단계에서 처리되는 오류
- 알 수 없는 토큰
- 소스 코드에서 유효하지 않는 토큰을 찾을 수 있다.
- 정의되지 않은 기호나 키워드가 아닌 문자열이 있는 경우
int x = @20;- 여기서
@는C++에서 유효한 연산자나 기호가 아니기에 어휘 분석 단계에서@를 인식하고 오류를 발생시킬 수 있다.
- 문자 리터럴 오류
- 문자열 리터럴이 제대로 닫히지 않는 경우
string str = "Hello;
정규 표현식으로 토큰 생성하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
enum TokenType
{
KEYWORD,
IDENTIFIER,
NUMBER,
OPERATOR
};
struct Token
{
TokenType type;
string value;
};
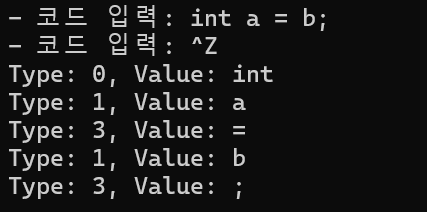
void Tok()
{
vector<pair<regex, TokenType>> token_patterns; //우선 순위대로 토큰 타입 넣기
token_patterns.push_back({ regex(R"(int|if|else|for|while|return)"), KEYWORD }); // 예약어
token_patterns.push_back({ regex(R"([a-zA-Z_][a-zA-Z0-9_]*)"), IDENTIFIER }); // 식별자
token_patterns.push_back({ regex(R"([0-9]+)"), NUMBER }); // 숫자
token_patterns.push_back({ regex(R"([+\-*/=;])"), OPERATOR }); // 연산자
int patternSize = token_patterns.size();
vector<Token> tokens;
smatch match;
string line;
while (true)
{
cout << "- 코드 입력: ";
getline(cin, line);
if (cin.eof())
{
break;
}
if (line.empty())
{
continue;
}
string::const_iterator searchStart(line.begin());
while (searchStart != line.end())
{
bool matched = false;
for (const auto& p : token_patterns)
{
regex pattern = p.first;
TokenType type = p.second;
if (regex_search(searchStart, line.cend(), match, pattern) && match.prefix().first == searchStart)
{
Token token;
token.type = type;
token.value = match.str();
tokens.push_back(token);
searchStart = match.suffix().first;
matched = true;
}
}
if (matched == false)
{
cout << "사용 가능한 토큰이 없습니다. " << *searchStart << endl;
}
}
}
cin.clear();
for (auto token : tokens)
{
cout << "Type: " << token.type << ", Value: " << token.value << "\n";
}
}
결과